

Welcome to the fifth part of our implementation series of a BPMN model in (Java) code! We came a long way and only two parts of this series are remaining. Today we deal with the problem of hanging threads, which we postponed until now.
If you haven't read the previous parts, please read them first to get to know the context:
Part 1,
Part 2,
Part 3,
Part 4.
Short Recap
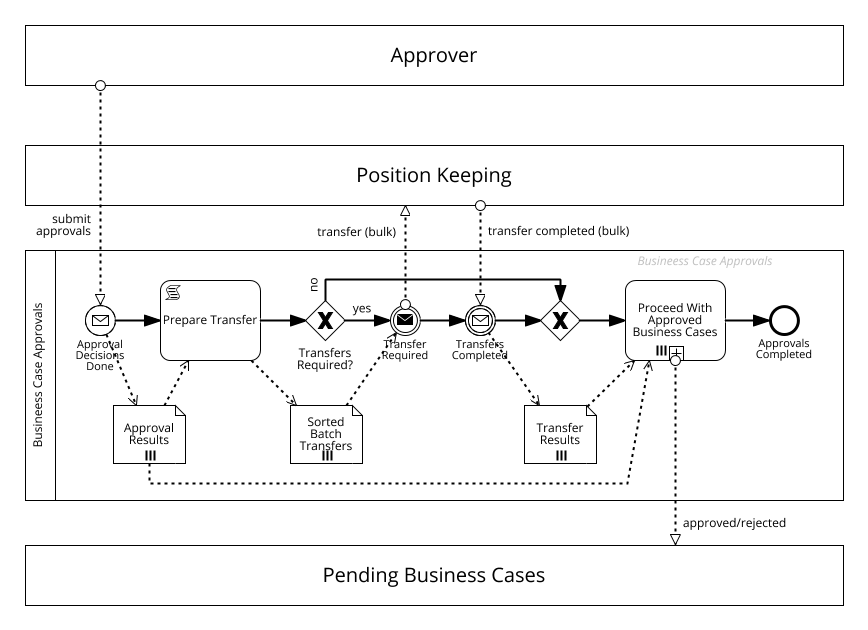
The figure above shows our current state of the approval process model: The process receives a set of approvals and initiates transfers based on those - if there are any. At the end, all pending business cases waiting for approvals and possibly transfers are notified that they can proceed (or that they need to abort).
Waiting for messages - forever
We are now going to address the problem of a possibly infinite wait for the callback message (transfer completed), which indicates that the transfer operation has been completed. In general, we have a problem when we are waiting for external events. In this example it is a bit more exposed because we have a thread waiting but in the end this problem always arises, whenever we wait for external events. And this problem arises regardless of the implementation strategy (different software architectures, workflows, ...) and the external trigger type (callbacks, events, ...)!
In our implementation so far the problem manifests itself in the following line, which the process threat uses to wait for the receive of a message:
messageLatch.await();
Why is infinite waiting a problem? Well, it is in two dimensions: First, it consumes resources in the software system (technical dimension). Depending on the implementation strategy these resources matter more (threads) or less (database space) but in the end we have some unfreed resourced here. Secondly, it hinders the completion of (a possibly important) business activity (business dimension).
The missing event can also arise out of these two dimensions:
- A software system might have "forgotten" to send the message/event/... due to a software defect, unavailablity or a similar technical reason,
- A business transaction can be stuck at some step due to missing or belated user input, missing reponsibilities etc.
Accordingly, solutions and mitigations to this problem can be technical (e.g., re-sends of messages) but very often also have business impact. Sometimes they are even in between by raising issues to a technical support team, which can be a dedicated unit or would be done by the developers in DevOps scenarios. In this article we will explore 3 typical strategies to deal with this.
Re-Triggering the Message
After waiting for a defined time the process "escalates" the missing message to a mechanism that tries to recover the message. After escalation the process is still waiting for the message to arrive in order to proceed normally. Recovery operations can be chosen from a wide range of options: The system can resend its message and hope that it then receives a reply or it can escalate the problem to a human handler (e.g., support team, superior in the organization, ...).
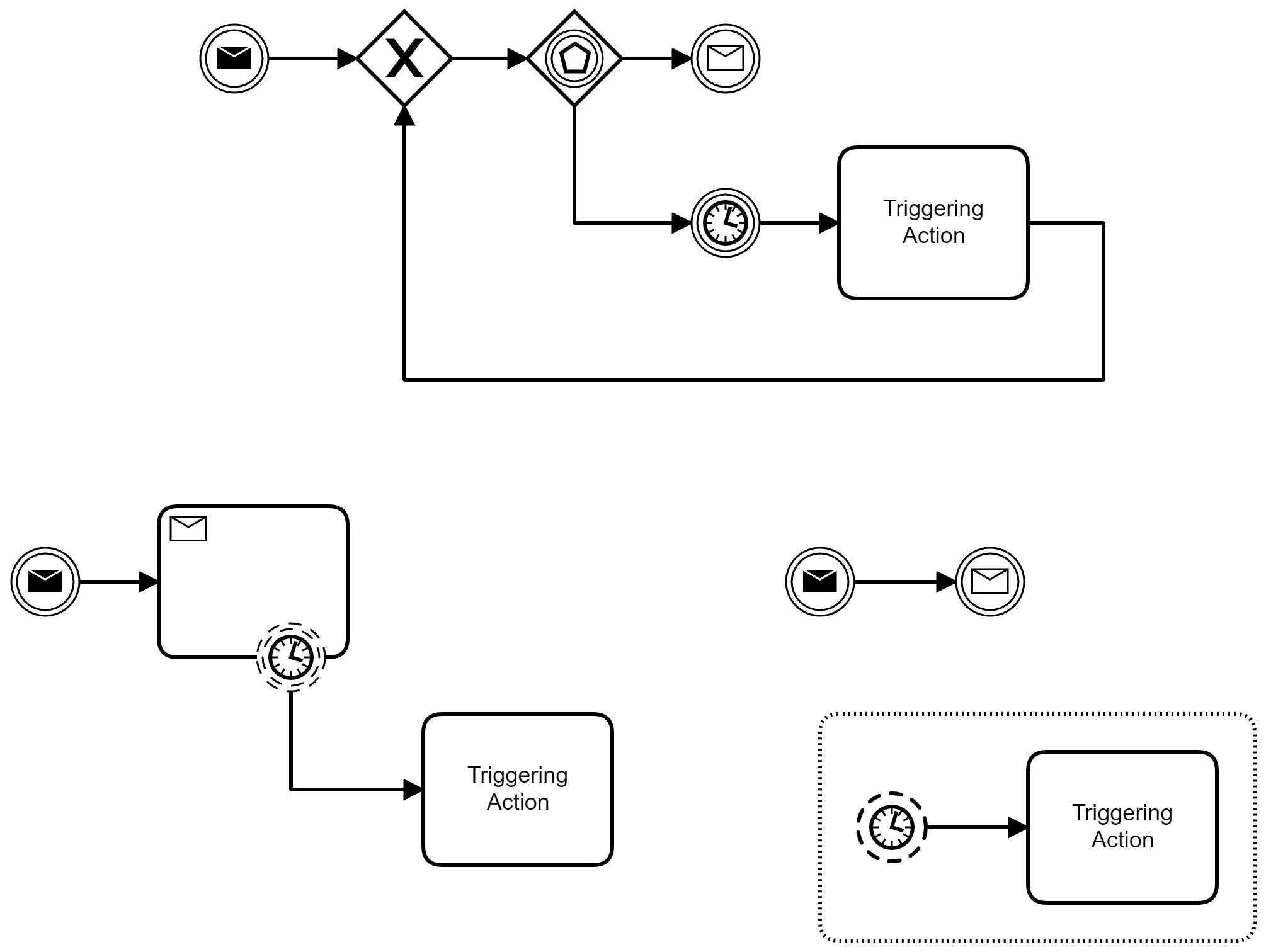
Three different options on how to model this behavior in BPMN are shown above. All three will do more or less the same but unfortunately there are multiple ways to express the desired behavior in BPMN.
The first one is the most "procedural" one, which uses less sophisticated constructs: After sending the message the process waits for two events: the message or a time. The waiting is expressed by an event-based gateway, which triggers the path that is indicated by the event that is received (message) or reached (time) first. When the deadline is reached, the process initiates an operation that triggers the incoming message to be sent and then waits again for the message.
The second option is the use of a non-interrupting boundary event. A boundary event is an event that is placed on the border of an activity and is activated when the activity is active. In this case the activity is a receive task that waits for the incoming message. Because the boundary event is non-interrupting as indicated by the dashed border, the receive task is still active after this event has been triggered. The branch from the event is executed in parallel to the message receive.
The third option is an event-based subprocess. The subprocess is active when the parent process is active. The dashed lines of the start event in the event-based subprocess resembles the style of the non-interrupting boundary event and it serves the same function: The contents of the event-based subprocess is executed in parallel to the rest of the process upon activation by the non-interrupting start event.
The action to re-trigger the event can be also chosen from lots of options (it is also possible to use different ones in a kind of escalation ladder): For instance, a resend of the request message can be done to see, if an answer is received back. The process can inform the support team (e.g., by an error message log) and/or it can present a human task or send an email to some business team leader to check what to do.
Compensating Variants
Sometimes the missing event can be compensated, i.e., an alternative solution or data is taken. For example, if different suppliers are asked for a bid, a missing message from one supplier can be ignored or a default worst-case value be used instead. In such a scenario, the waiting for the external event would be interrupted and another path is taken.
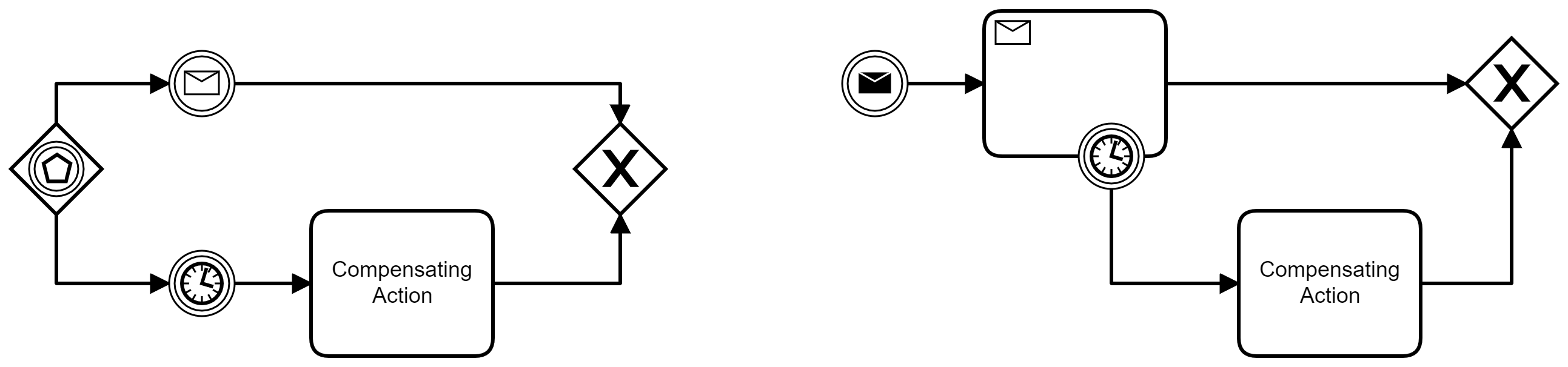
A compensating scenario can be modeled in two ways in BPMN as shown in the figure above: Either with an event-based gateway or with an interrupting boundary event. In both variants the control-flow is joined together using an XOR gateway so that the process can continue from there.
Error Variants
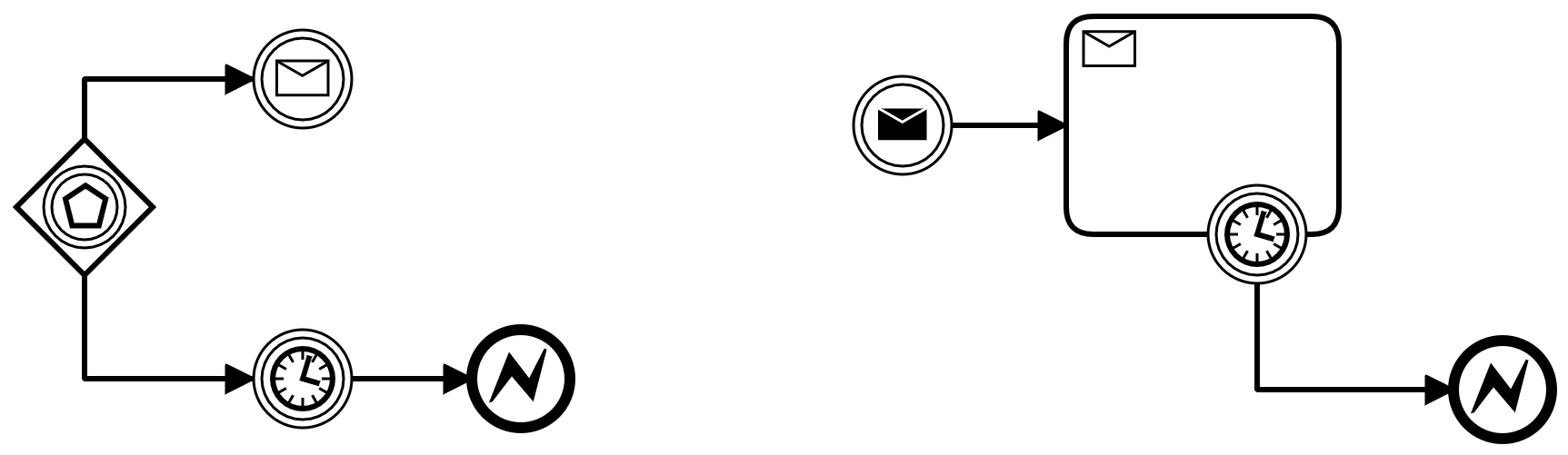
A third option is to convert this missing external event to an explicit error and signal this failure to the initial caller. The basic structure is the same like the compensation but instead of compensating the problem an error is thrown and the process is aborted.
Example Update
In our process the bulk transfer of mortgages is fully automated, i.e., it is highly likely that some implementation error or infrastructure downtime occurred so that the notification does not arrive. As such, we decide to escalate this issue to a support team. The updated process diagram is shown below.
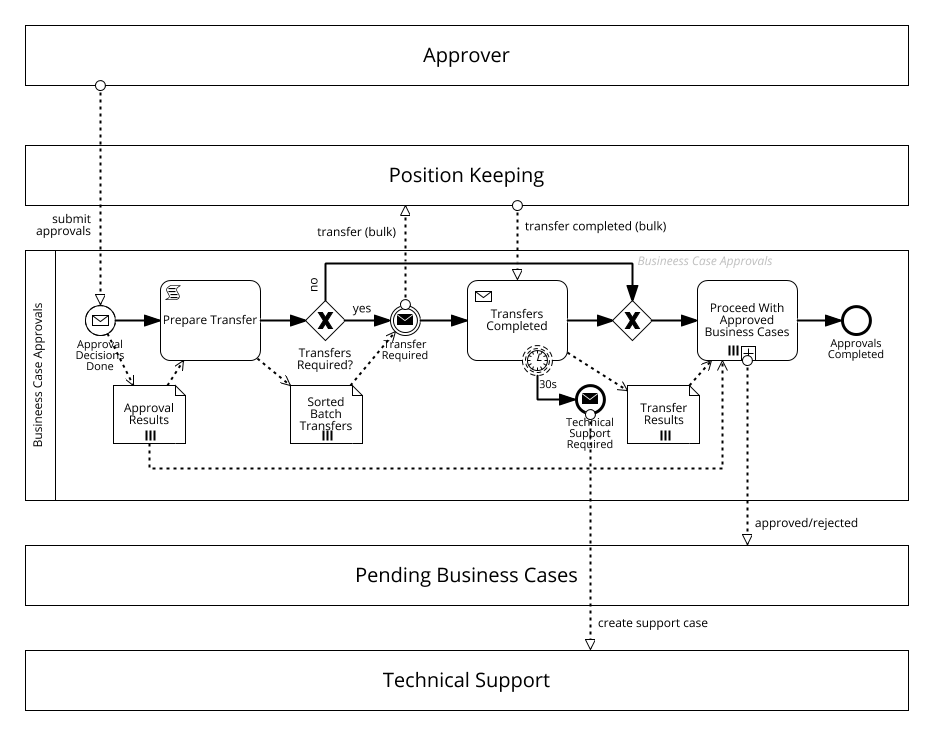
Implementation
Depending on the process implementation strategy the implementation of the timeout can be easy or requires some internal scheduling itself.
Because we have consolidated our whole process logic within a single thread (due to the short-running nature of this process), it is simple to extend our example to implement a re-triggering strategy.
All in good frameworks and libraries methods that suspend a thread are overridden with a variant that accepts a timeout.
After this, the waiting state is left and the failed state is signaled back to the calling code.
In our case, we use the latch's await(long, TimeUnit) method, which returns a boolean whether the return is successful or due to a timeout.
The updated code looks like this:
public class ApproverProcess {
private static final Logger LOG = System.getLogger(ApproverProcess.class.getName());
private PositionKeepingService positionKeeping;
private CountDownLatch messageLatch = new CountDownLatch(1);
private TransferCompletedMessage message;
public void approvalDecisionsDone(List<ApprovalResult> approvalResults) {
List<BatchTransfer> sortedBatchTransfers = prepareTransfers(approvalResults);
transferSecurities(sortedBatchTransfers);
proceedWithApprovedBusinessCases(approvalResults, sortedBatchTransfers);
}
private List<BatchTransfer> prepareTransfers(List<ApprovalResult> approvalResults) {
return null;
}
private void transferSecurities(List<BatchTransfer> sortedBatchTransfers) {
if(!sortedBatchTransfers.isEmpty()) {
positionKeeping.transferBulk(sortedBatchTransfers);
waitForTransfersCompleted();
}
}
private TransferCompletedMessage waitForTransfersCompleted() throws InterruptedException {
messageLatch.await();
if(!messageLatch.await(30, TimeUnit.SECONDS)) {
escalateToSupportTeam();
messageLatch.await();
}
return this.message;
}
private void escalateToSupportTeam() {
LOG.log(Level.ERROR, "Message not arrived for this process");
}
public void messageReceived(TransferCompletedMessage message) {
this.message = message;
messageLatch.countDown();
}
private void proceedWithApprovedBusinessCases(List<ApprovalResult> approvalResults,
List<BatchTransfer> sortedBatchTransfers) {
}
}
The changes in the code are small in comparison to the visual changes in the BPMN diagram.
You might, however, wonder why the logging statement, which is one line only, resides in its own method.
Actually, I initially wrote the log statement directly in the waitForTransfersCompleted method and decided to refactor this out later by using the "extract method" refactoring.
Why?
Simple:
The log statement itself conveys no business intention and that's crucial here!
The part of the logic that logs an error, generates an email from this and raises a new ticket is not part of our code but is part of many configuration files.
Thus, I decided to create a new method that allows me to give it a name that clearly conveys its intention.
We have now optimized our example and made some decisions on how to support our system in case of missing messages. In the next part of this series I want to discuss other implementation options for this process. So stay tuned!
If you found this article interesting and you do not want to miss following episodes and other articles, please consider subscribing for article updates below - do not miss any interesting content!