

A while back I needed to model a development process of a company. While creating the model I realized that the process-flow got quite complex, and I struggled to lay it out in an understandable way. That motivated me to do a little “experiment”: I described the process textually and send it to some colleagues who are very experienced with BPMN modeling. I did not send my BPMN diagram because I didn't want to influence the result. They should think about the layout themselves. Shockingly, none of the process models of my colleagues syntactically matched my process; thus, my experiment had failed to explore different layout options. However, it revealed some insights into possible modeling options for describing complex dependencies in a business process. The most interesting version was very, very simple. I will shortly describe the process and if you like you can try yourself how you model it. If you have done so or just want to get to the discussion, please scroll down.
To develop a new profile the implementation of a validator the implementation of a simulator and the definition of example messages are started in parallel. Example messages contain correct and incorrect messages. These example messages are preconditions for testing the validator and testing the simulator. Both test activities can start after the respective implementation has been completed. Additionally, to test the simulator, the validator must have been implemented but not yet tested. If both the tests of the validator and the simulator are completed the development of the profile is completed.
Scroll down to see the diagram.
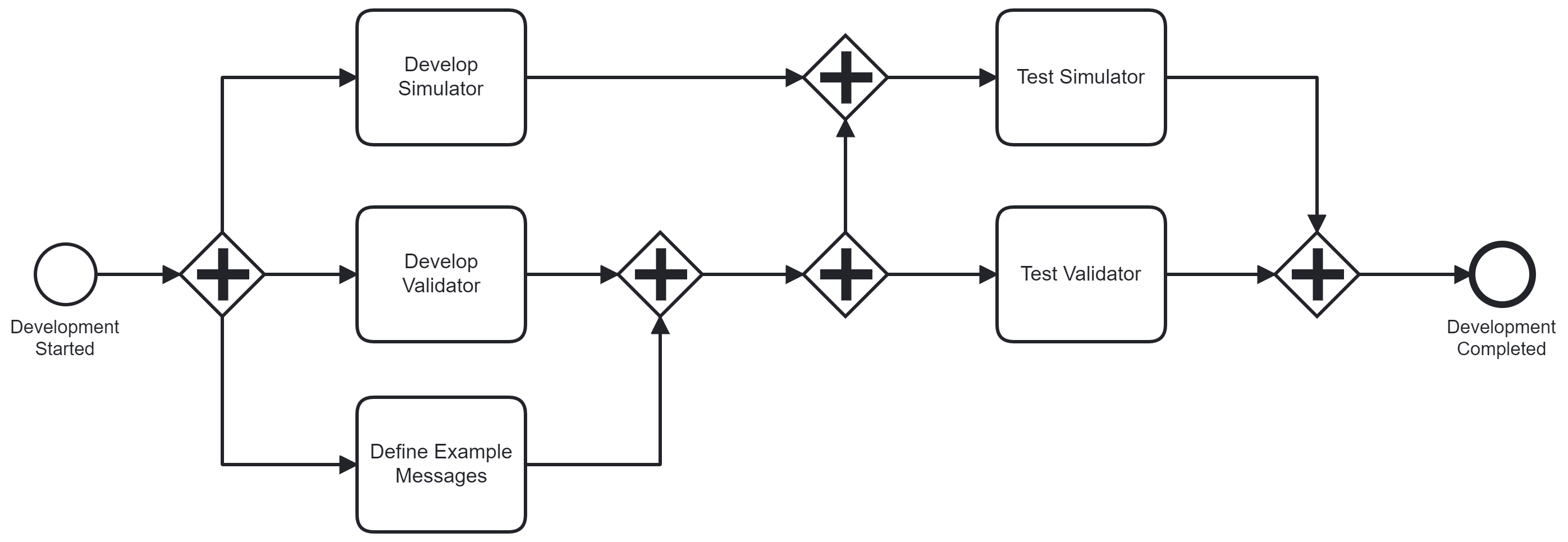
My way of modelling this process is shown above and probably what you expect. As you can see, I expressed the dependencies by using sequence flows and gateways to order the given tasks. This gets complicated with many edges, which in turn are hard to lay out. Thus, my motivation to explore (better) layout options.
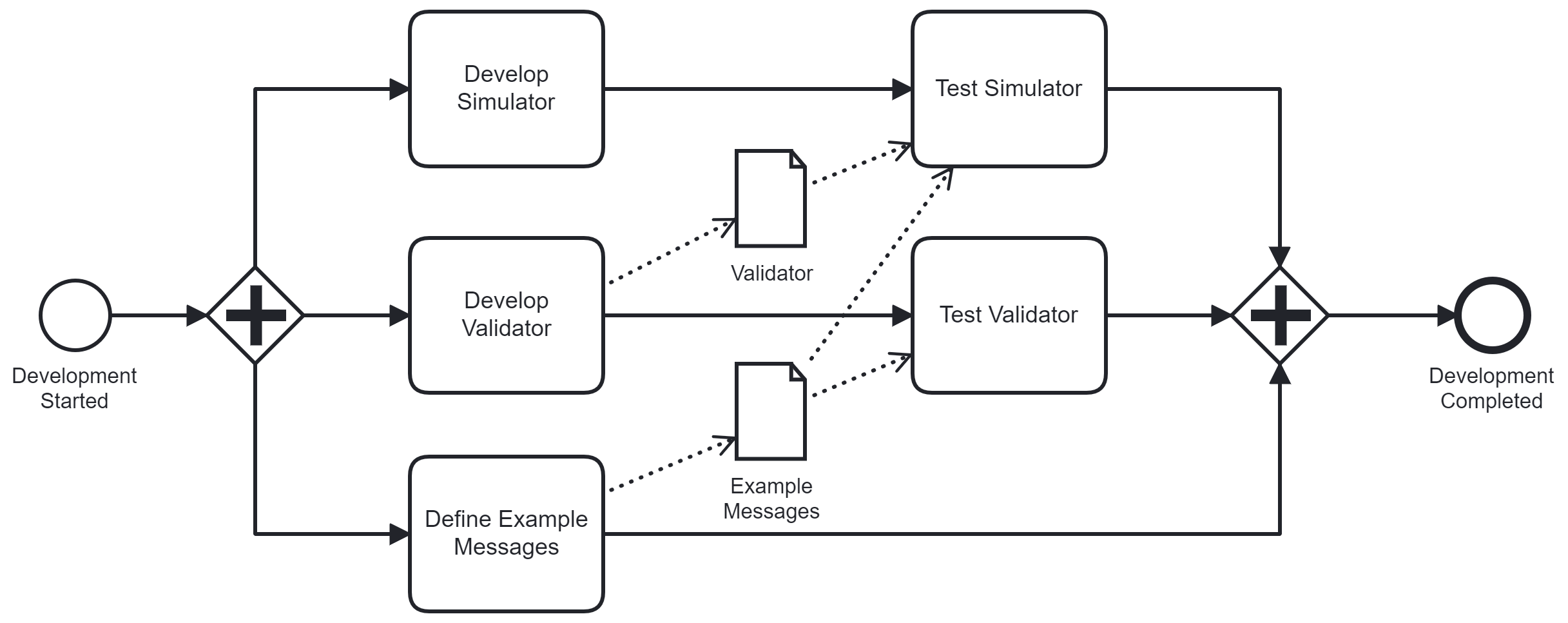
However, a colleague came up with a much better solution - at least visually his process model is much cleaner as shown above. You might ask whether this process model is correct and corresponds to the sceneario and the answer is yes: The dependencies between the tasks are not modeled with control-flow constructs but instead with data objects. Not all BPMN modelers know this, but BPMN allows to specify requirements on data availability before a task can start. I expect that most people will interpret this model in the correct way. If they should perform a task and the required data is not available they will postpone this task. However, most BPMN engines cannot correctly execute this model. Also, data flow pre- and post-conditions can get complex more quickly and require some task properties, which are not visible but are stored in properties in the process model (data input and output sets anyone?). There might be no intuitive way to understand such business process models. As a consequence, one might argue whether using these data-flow definitions is a good idea in general. In most scenarios, which I have encountered in my projects, expressing dependencies with the control-flow, i.e., sequence flows and gateways, is fine and also probably more readable and understandable for model consumers. However, I think this case is one of the examples in which using data-flow gives us a better comprehensible and thus better business process model.
I encountered this process some years back and as such my “experiment” is quite old. However, I was reminded of it last week: a PhD student named Maximilian König presented his approach to formalize data-flow in BPMN at the ZEUS workshop. You can find his paper here. I think it would be great, if in the future BPMN engines would be able to handle data-flow and data dependencies in a more standards-compliant way.
What do you think? Is expressing dependencies via data-flows good or bad? You can leave a comment on LinkedIn and take part in this discussion!
|
<<< Previous Blog Post BPMN’s Most Undervalued Elements? Start and End Events |
Next Blog Post >>> Interview with Eric Wild and Daniel Lübke about Microservice API Patterns |