

While Camunda covers this topic in the documentation, I personally only got a full grasp on asynchronous continuations after playing around with them in different scenarios. This is why I want to highlight some insights on the impact they can have on processes that might not be completely clear just by reading the documentation. I do not guarantee a holistic summary of the topic, but I still hope you can take away something useful! Let's start with an introduction to familiarize ourselves with transactions in Camunda processes.
Introduction
The Camunda Platform 7 Process Engine splits processes into multiple database transactions, that get committed only when a "wait state" is reached in the process execution. Some BPMN elements are always wait states, including:
- User Tasks
- Receive Tasks
- Intermediate Message Timer and Signal Catch Events
- Event Based Gateways
- External Tasks (Service Tasks or Message Catch Events with implementation = external)
Everything that happens between two wait states is handled in memory. This allows the engine to perform a series of tasks (for example Script Tasks or Service Tasks) quickly without having to wait for slow persistent storage. But performance is not the only implication from long transactions. They also effect communication with surrounding systems as well as the handling of error scenarios. Let's take a look at this simple example with no wait state:
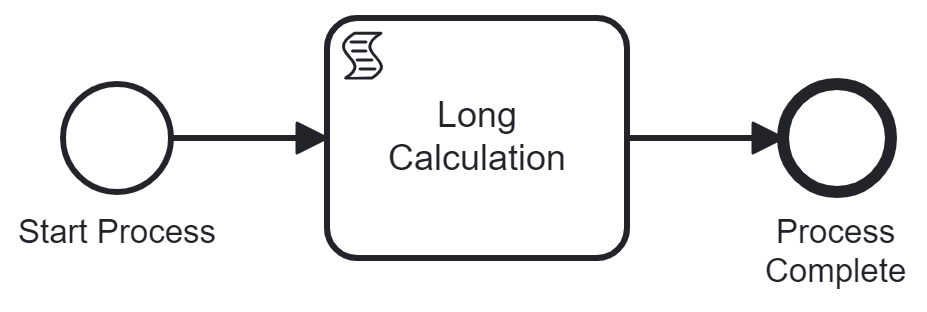
If this process is started, for example using the REST API, the caller will have to wait for the long calculation to be completed to finally get a response. Also note that, since nothing is written to the database until the process instance is completed, operators would not be able to see any progress in this kind of process in tools like Camunda Cockpit.
In this case, the whole process is executed synchronously. The example shows, how this performance optimization by the process engine can have negative effects on the performance or the load of the caller, if this synchronous behavior is not intended. But there is more to consider. The probably most common impact of long transactions in processes is, that in failure scenarios, the whole transaction is rolled back. This means if the long calculation above throws an exception, the caller will receive the error information. And since no transaction has ever been committed, from an operators perspective looking at the history in Cockpit, Optimize, or similar tools, no signs that an instance was started are visible at all.
While this behavior might be useful in some scenarios, it can lead to serious problems including:
- Difficulties analyzing errors
- Unnecessary blocked resources on surrounding systems
- Multiple executions of non-idempotent tasks
- Wrong process statistics
This is why Camunda offers developers the option to set additional transaction boundaries in the process models called asynchronous continuations (ACs). ACs can be set before and/or after any flow object. With the introduction from above, the name makes sense because until an AC is reached, the process executes synchronously in the context of the caller. After the AC, the job executor takes over to process asynchronously from the original call.
Timing of Transaction Boundaries
But when exactly do transaction boundaries occur? The following diagram shows the process for a script task with ACs before and after in the middle of some process.
On the top, the task is shown with one incoming and one outgoing sequence flow. On the bottom, the actions performed by the engine for this task demonstrate what happens in each of the three transactions. Everything before the task (this would include take listeners on the sequence flow, not displayed here) belongs to T0 which is committed before any actions for the task are performed. Afterwards, the input mappings, start listeners, the actual task behavior, output mappings and end listeners are invoked in a single transaction (T1) that is committed right after this. The rest of the model is executed in a different transaction (T2).

I illustrate this lifecycle in detail because it showcases an important aspect of ACs, especially when working with natural wait states like user tasks. In their documentation, Camunda recommends, as a general strategy, to not configure ACs before natural wait states, as this would introduce overhead. But there is an important semantic difference between a natural wait state and AC-before. This is shown in the following diagram. Here, a user task is shown with only AC-after configured (note that there might be more transactions involved with user tasks that are assigned, updated etc. that are not shown here, also task listeners are omitted). Because the wait state is reached only after input mappings and start listeners are already completed, the transaction boundary for T0 shifts compared to the script task example above.

If AC-before is configured on the other hand, the input mappings and start listeners are handled with a completely new transaction:

This can have impact on the process behavior, as, for example, a failure of a start listener would result in an incident with AC-before configured, while it might be included in a synchronous call to a start event or similar, depending on the rest of the process, if AC-before is not configured.
But this problem could be avoided by configuring AC-after for every flow object, right? Well, yes. But there can still be use cases in which setting AC-before for wait states can be useful. For example, Camunda offers a mechanism to suspend job definitions. When AC-before is configured, this would allow you to disable certain external tasks temporarily (for example, because a service is down) by suspending the job definition for the AC. This can be configured for example in Camunda Cockpit as shown below.
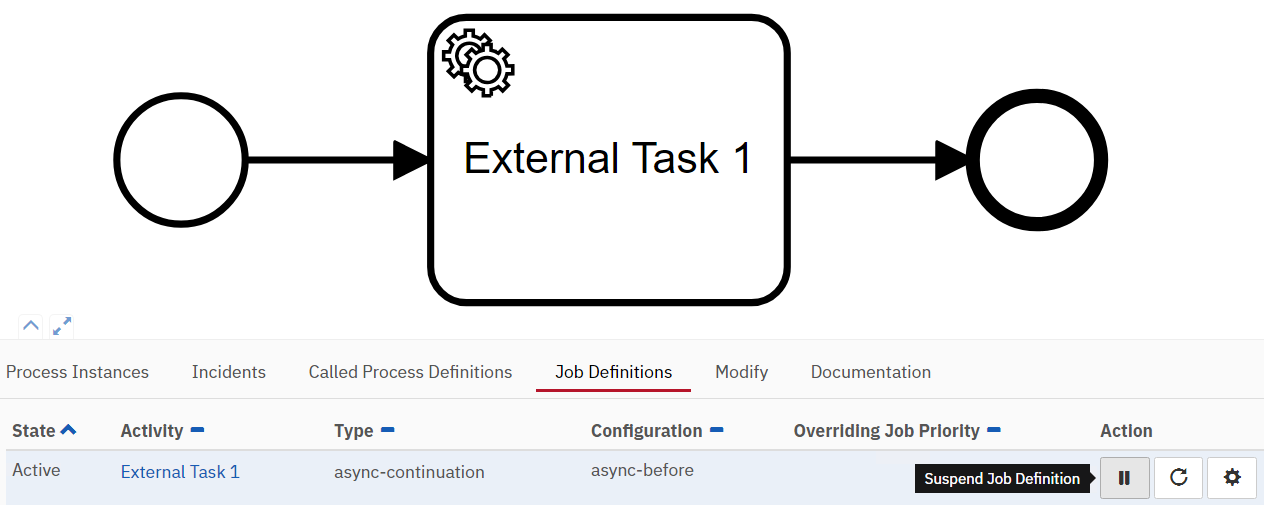
So, does this mean we should set AC before and after on every flow object to ensure errors always appear where we expect them? I argue no! And not only because of the performance implications from all the database operations.
To elaborate, let's have a look at another Camunda guideline. It is recommended, that for start events, AC-before should be set. This ensures that every started process instance is immediately persisted to the database. But this also excludes any scripts that might be attached to the start event from the synchronous call. Thus, no input validation of any kind can be performed before the execution is detached from the caller. While this can be intended to provide maximum insight and control to an operator using Cockpit, in my opinion, it is not the most requested behavior. Starting a process with invalid starting data would result in an incident on the start event, while an error would be returned to the caller if no AC-before is set without committing to the database at all. I would make the same argument for intermediate message catch events.
Process Instance Modification
Camunda offers operators the possibility to modify running process instances. The behavior for this can be confusing, especially if no ACs are set.
The model below is used to demonstrate my point. I am using the Camunda Transaction Boundaries Plugin to show where ACs are configured. Let's imagine Task X throws an exception which leads to an incident (note AC-before on the task). To resolve the incident, an operator modifies the process instance by moving the token from Task X to one of the end events (End Event B0 or B1). This can be done using the enterprise version of Camunda Cockpit or with just a few lines of code like this:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery().singleResult();
ActivityInstance subProcessInstance = runtimeService.getActivityInstance(processInstance.getId()).getChildActivityInstances()[0];
runtimeService.createProcessInstanceModification(processInstance.getId())
.startBeforeActivity(endEventId, subProcessInstance.getId())
.cancelAllForActivity("taskX")
.execute();
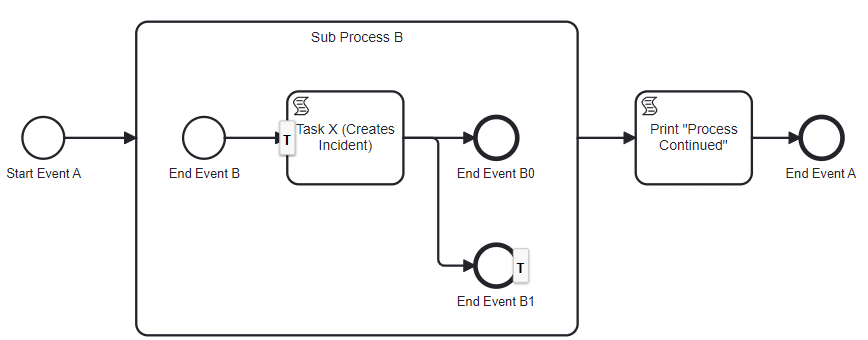
The operator expects the process instance to stay alive and thus "Process Continued" should be printed.
This only happens with endEvent = "endEventB1" though. With endEvent = "endEventB0"
on the other hand, the subprocess and the process instance are canceled, and the second script task is never
reached.
For the operator this can be extremely confusing because by default, the transaction boundaries are not visible
immediately in the BPMN diagram.
Other Considerations
In some cases, it is necessary to set ACs to prevent race conditions or optimistic locking exceptions. However, I will not go into much detail in this blog article. For example, consider the following process:
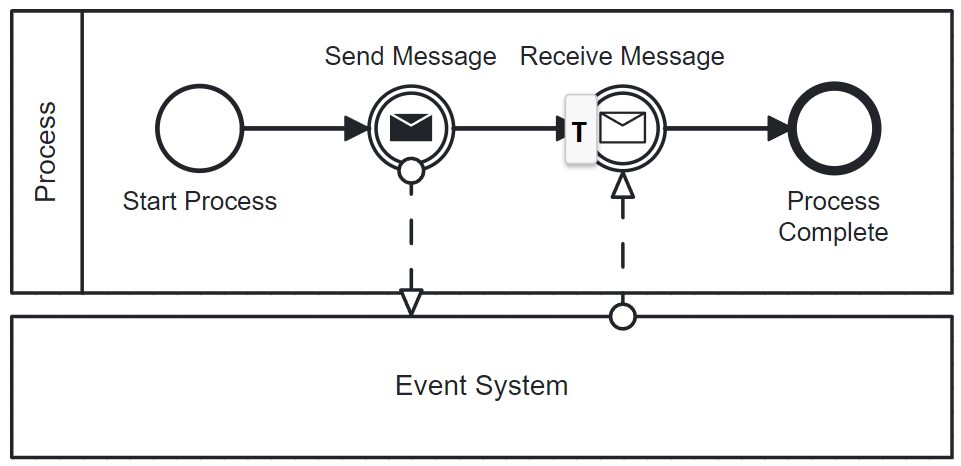
The process sends a message after which it awaits a response. But the problem is, that there is a race condition. If the response is sent right after the original message is sent, the process engine might not be waiting for the response yet. To prevent that, a parallel gateway can be used in combination with AC-before on the message throw event to ensure that the message catch event is committed before any message is sent out.
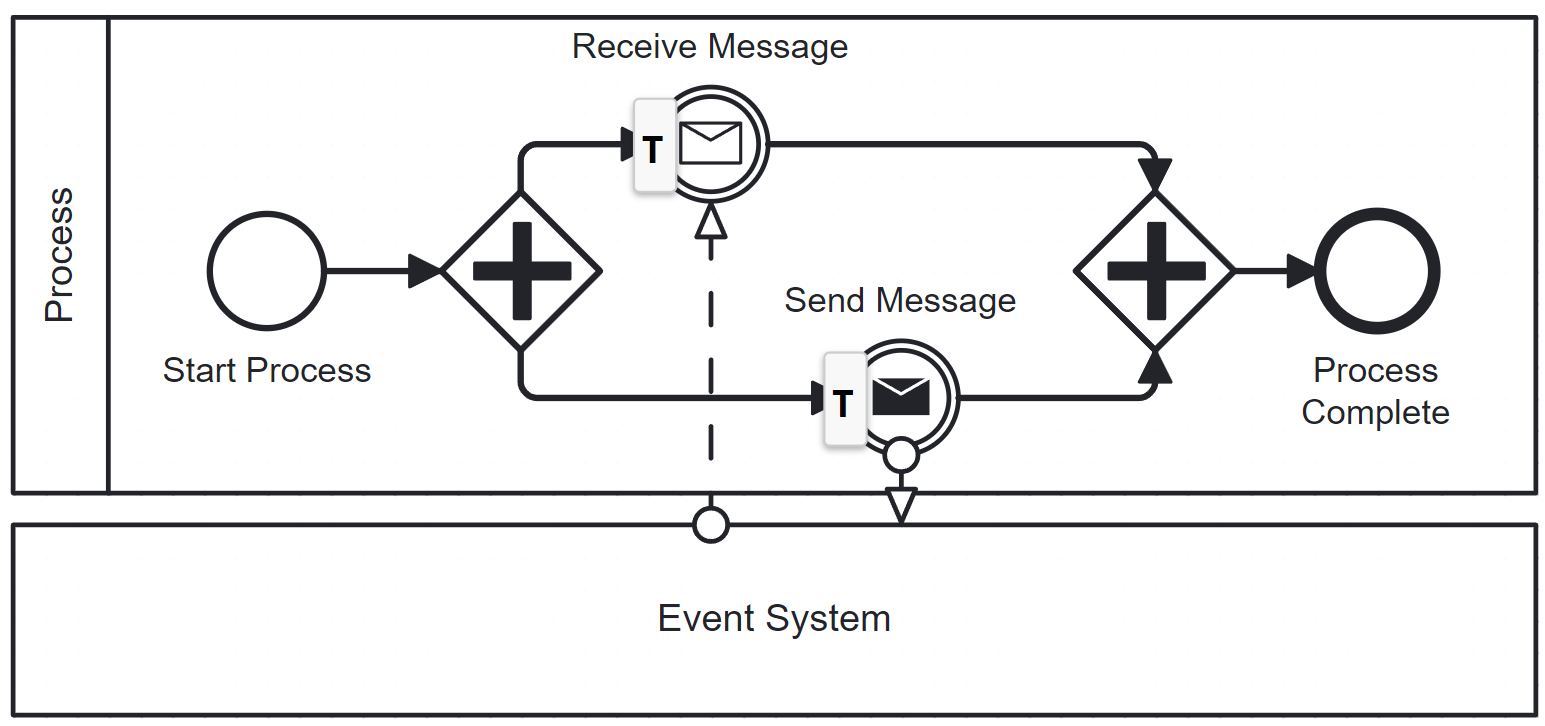
Another scenario in which ACs can be useful is when using parallel joins. Here some optimistic locking exceptions can be prevented by setting AC-before on the join.
My Recommendations
Considering my argumentation, what AC policy should be used? As almost always, I have to conclude that it depends on the circumstances. I definitely recommend setting guidelines for your own projects, so the processes behave consistently. The individual guidelines within the projects depend on multiple factors though, like:
- Performance Requirements
- Operatability Requirements
- Architecture (for example, are you using external tasks or delegates?)
- BI and Reporting Requirements
- Your own preference (do you use execution listeners or I/O-Mappings?)
In the end, the most important thing is that you understand why your processes behave the way they do.
|
<<< Previous Blog Post What are Challenges with our APIs? |
Next Blog Post >>> API Contract equals More Freedom |